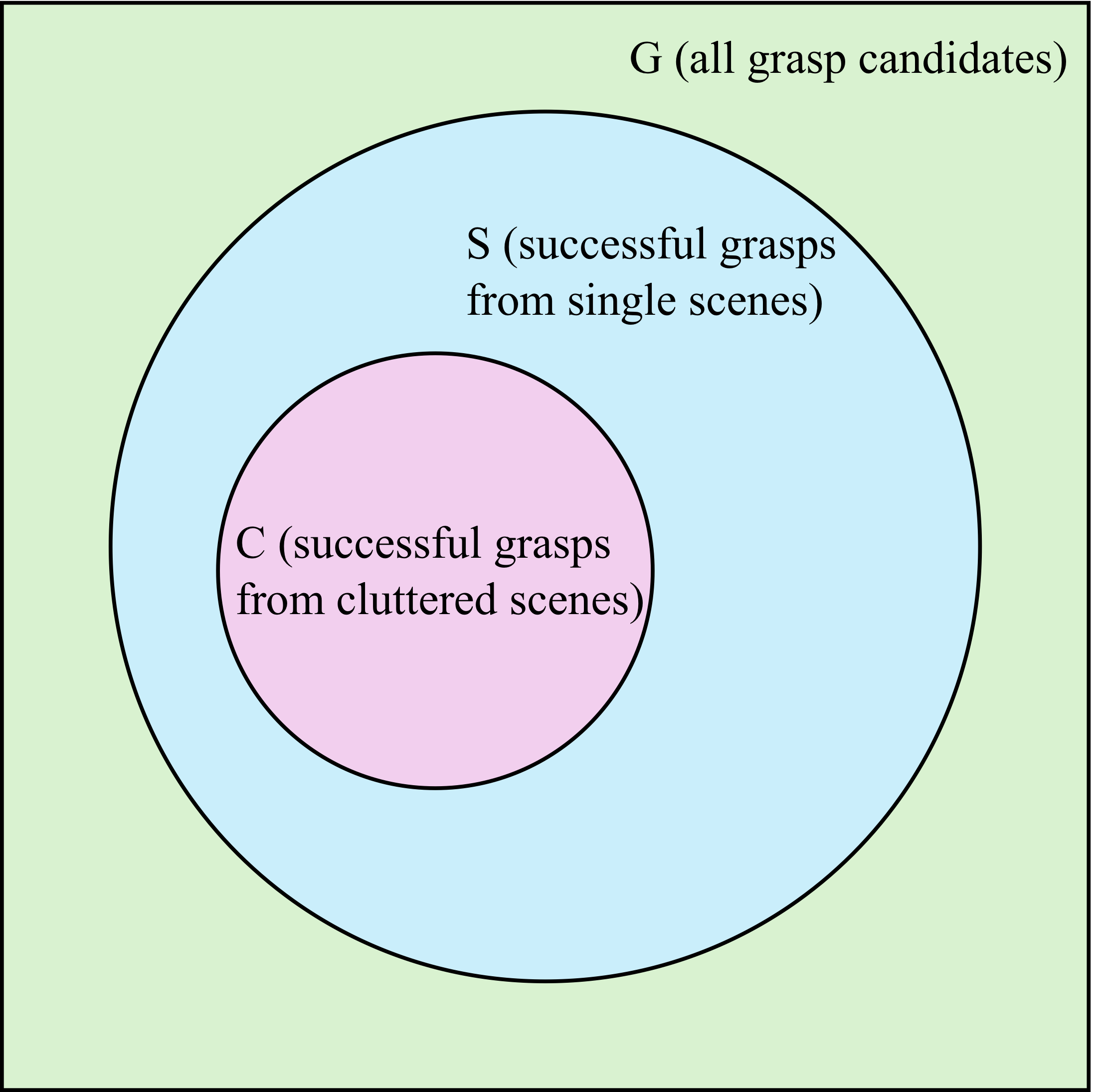
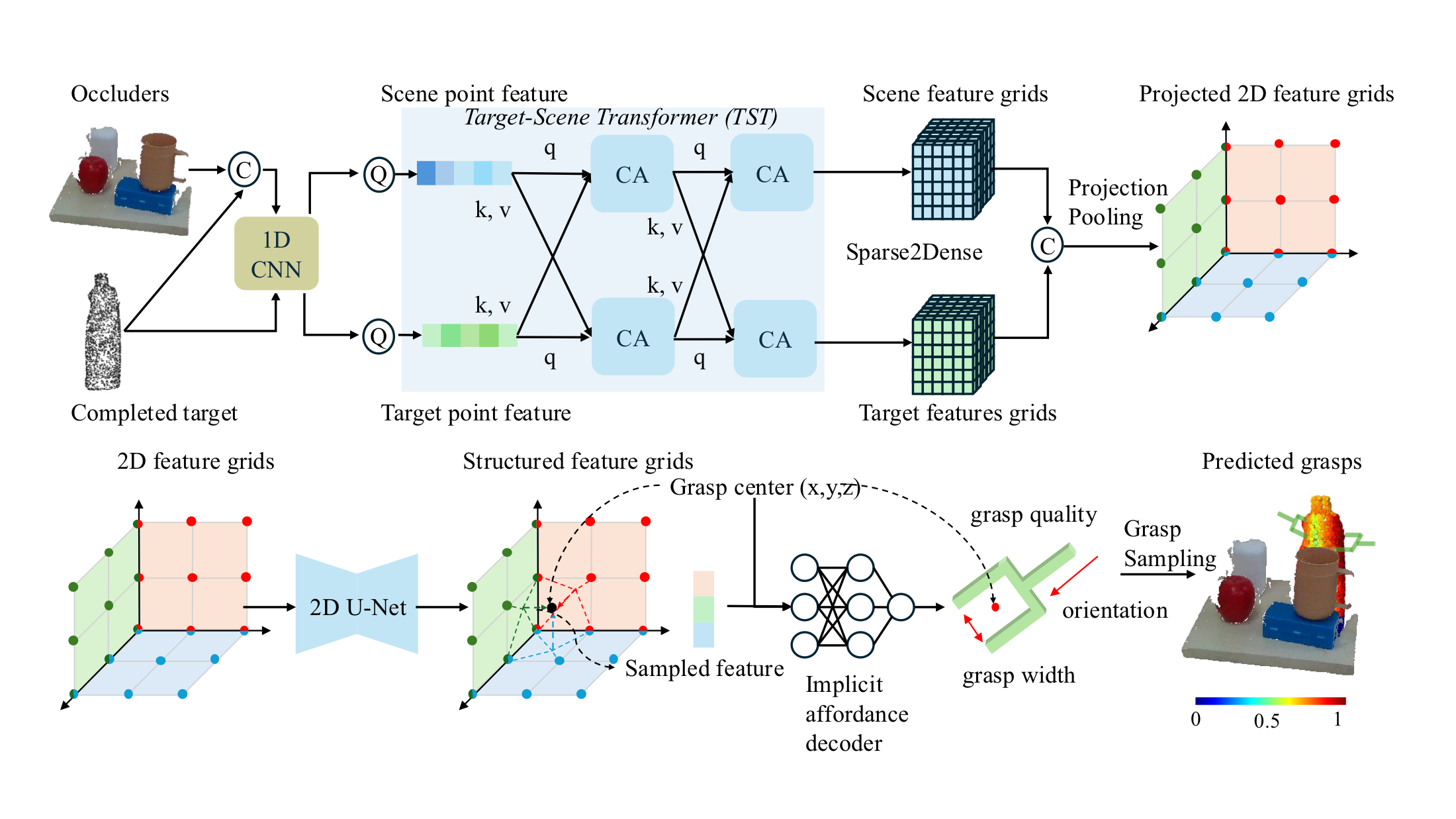
TARGO Dataset

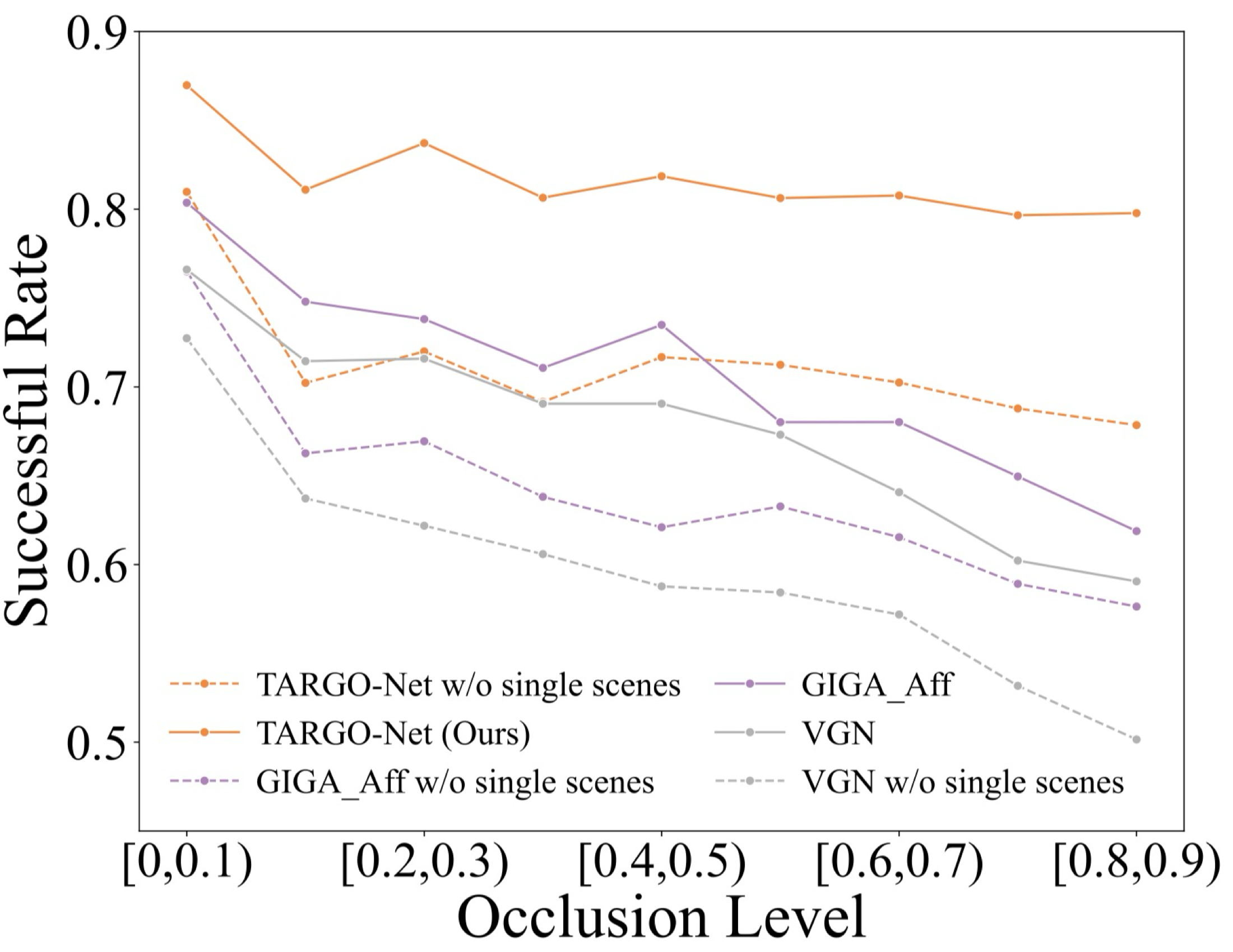
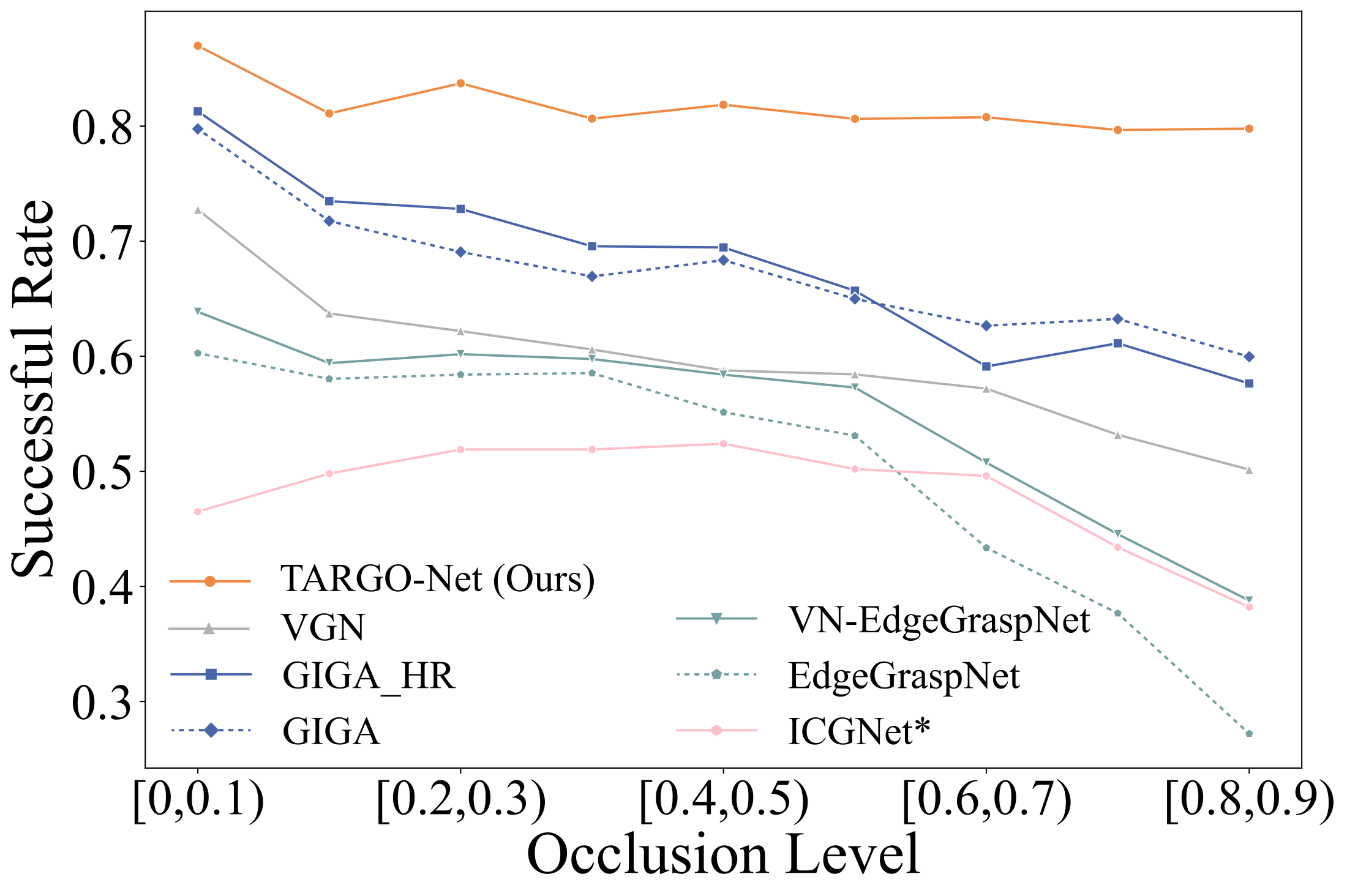
TARGO-Synthetic is constructed using VGN objects in PyBullet. Random placement naturally produces many low-occlusion scenes, which are useful for training but insufficient for stress-testing occlusion robustness.
To avoid overestimating performance on easy scenes, the benchmark includes a balanced test set with 1,000 scenes for every occlusion level from 0 to 0.9. TARGO-Real further evaluates transfer to real-world cluttered grasping with a Panda arm setup.